堆这种数据结构的应用场景非常多,最经典的莫过于堆排序了。
堆排序是一种原地的、时间复杂度为 O(nlogn) 的排序算法。前面我们学过快速排序,平均情况下,它的时间复杂度为 O(nlogn)。尽管这两种排序算法的时间复杂度都是 O(nlogn),甚至堆排序比快速排序的时间复杂度还要稳定,但是,在实际的软件开发中,快速排序的性能要比堆排序好,这是为什么呢?
如何理解“堆”?
只要满足这两点,它就是一个堆。
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列
堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。实际上,我们还可以换一种说法,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫做“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫做“小顶堆”。
如何实现一个堆?
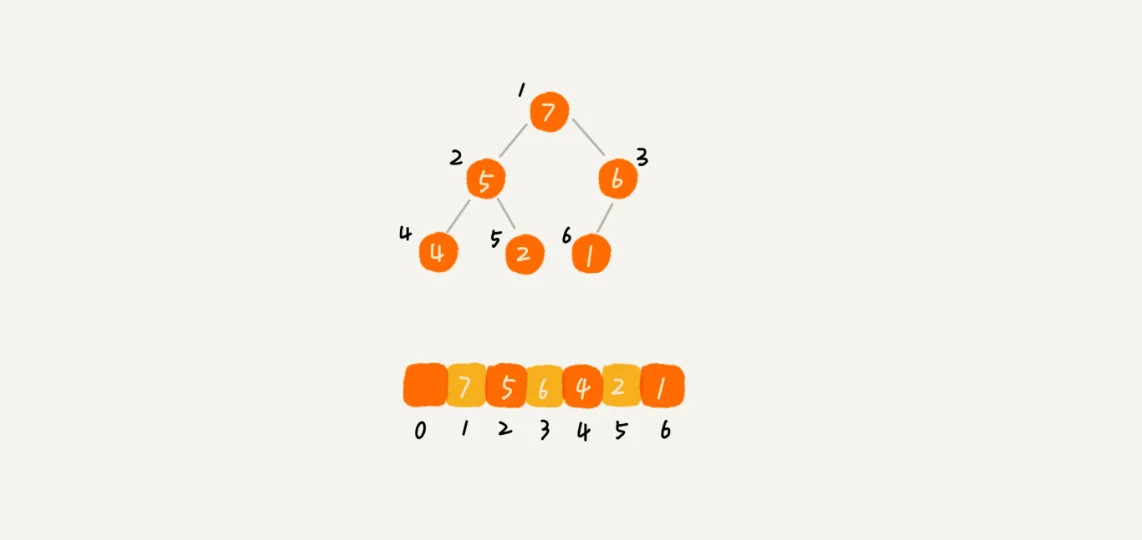
从图中我们可以看到,数组中下标为 i 的节点的左子节点,就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1 的节点,父节点就是下标为 2i 的节点。
往堆中插入一个元素 堆化(heapify)
我们可以让新插入的节点与父节点对比大小。如果不满足子节点小于等于父节点的大小关系,我们就互换两个节点。一直重复这个过程,直到父子节点之间满足刚说的那种大小关系。
删除堆顶元素
当我们删除堆顶元素之后,就需要把第二大的元素放到堆顶,那第二大元素肯定会出现在左右子节点中。然后我们再迭代地删除第二大节点,以此类推,直到叶子节点被删除
class MinHeap {
constructor() {
this.heap = [];
}
getParentIndex(i) {
// return Math.floor((i-1)/2);
return (i - 1) >> 1; // 右移一位 即除二取商操作
}
getLeftIndex(i) {
return i * 2 + 1;
}
getRightIndex(i) {
return i * 2 + 2;
}
swap(i1, i2) {
const temp = this.heap[i1];
this.heap[i1] = this.heap[i2];
this.heap[i2] = temp;
}
// 自下往上堆化
shiftUp(index) {
if (index === 0) return;
const parentIndex = this.getParentIndex(index);
if (this.heap[parentIndex] > this.heap[index]) {
this.swap(parentIndex, index);
this.shiftUp(parentIndex);
}
}
shiftDown(index) {
const leftIndex = this.getLeftIndex(index);
const rightIndex = this.getRightIndex(index);
if (this.heap[leftIndex] < this.heap[index]) {
this.swap(leftIndex, index);
this.shiftDown(leftIndex);
}
if (this.heap[rightIndex] < this.heap[index]) {
this.swap(rightIndex, index);
this.shiftDown(rightIndex);
}
}
insert(value) {
this.heap.push(value);
this.shiftUp(this.heap.length - 1);
}
pop() {
if (this.size() === 1) return this.heap.shift();
this.heap[0] = this.heap.pop();
this.shiftDown(0);
}
peek() {
return this.heap[0];
}
size() {
return this.heap.length;
}
}如何基于堆实现排序?
前面我们讲过好几种排序算法,我们再来回忆一下,有时间复杂度是 O(n2) 的冒泡排序、插入排序、选择排序,有时间复杂度是 O(nlogn) 的归并排序、快速排序,还有线性排序。
这里我们借助于堆这种数据结构实现的排序算法,就叫做堆排序。这种排序方法的时间复杂度非常稳定,是 O(nlogn),并且它还是原地排序算法。
- 建堆
第一种是借助我们前面讲的,在堆中插入一个元素的思路。尽管数组中包含 n 个数据,但是我们可以假设,起初堆中只包含一个数据,就是下标为 1 的数据。然后,我们调用前面讲的插入操作,将下标从 2 到 n 的数据依次插入到堆中。这样我们就将包含 n 个数据的数组,组织成了堆。
第二种实现思路,跟第一种截然相反,也是我这里要详细讲的。第一种建堆思路的处理过程是从前往后处理数组数据,并且每个数据插入堆中时,都是从下往上堆化。而第二种实现思路,是从后往前处理数组,并且每个数据都是从上往下堆化
- 排序
这个过程有点类似上面讲的“删除堆顶元素”的操作,当堆顶元素移除之后,我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了。
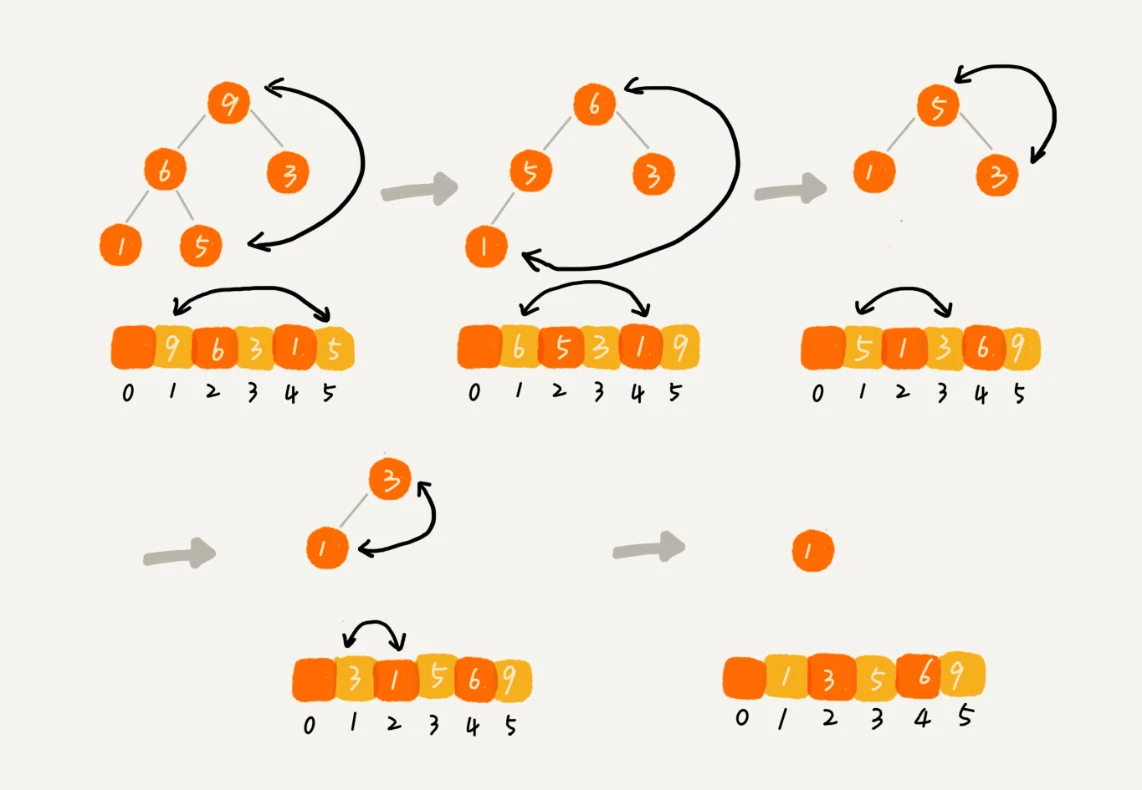
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法。堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
原文链接: https://jesse121.github.io/blog/articles/2021/03/16.html
版权声明: 转载请注明出处.