在日常开发中难免会遇到写正则匹配的问题,平时总是从网上搜搜看,写的也匹配不了。总觉得这块自己的缺陷比较大,于是就专门在极客时间上学习了下正则表达式课程,这里记下学习记录,希望学完后所有的正则问题都能迎刃而解。加油!
01 | 元字符:如何巧妙记忆正则表达式的基本元件?
正则常见的三种功能:
- 校验数据的有效性
- 查找符合要求的文本
- 对文本进行切割和替换等操作。
元字符的概念
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,元字符是构成正则表达式的基本元件
元字符的分类与记忆技巧
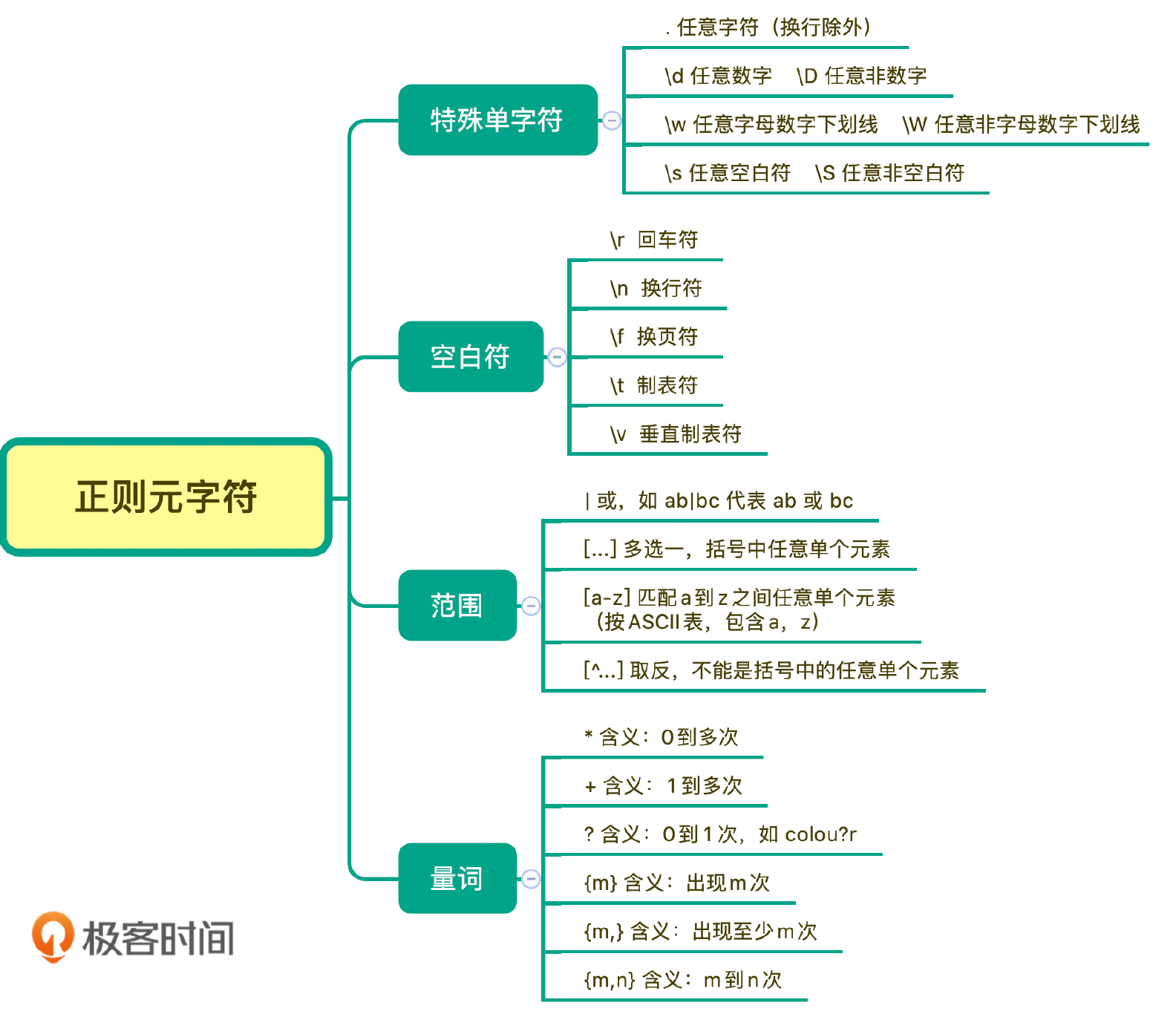
- 特殊单字符
- . 任意字符(换行除外)
- \d 任意字符 \D 任意非字符
- \w 任意数字字母下划线 \W 任意非数字字母下划线
- \s 任意空白符 \S 任意非空白符
- 空白符
- \r 回车符
- \n 换行符
- \f 换页符
- \t 制表符
- \v 垂直制表符
- \s 任意空白符
- 量词(匹配出现 0 次或多次)
- * :0 到多次
- + :1 到多次
- ?: 0 到 1 次
- {m}: 出现 m 次
- {m,} : 至少出现 m 次
- {m,n}: m 到 n 次
- 范围
- | 或
- […] 多选一 括号中任意单个元素
- [a-z] 匹配 a-z 之间的任意单个元素
- [^…]取反 不能是括号中的任意单个元素
总结
02 丨量词与贪婪:小小的正则,也可能把 CPU 拖垮!
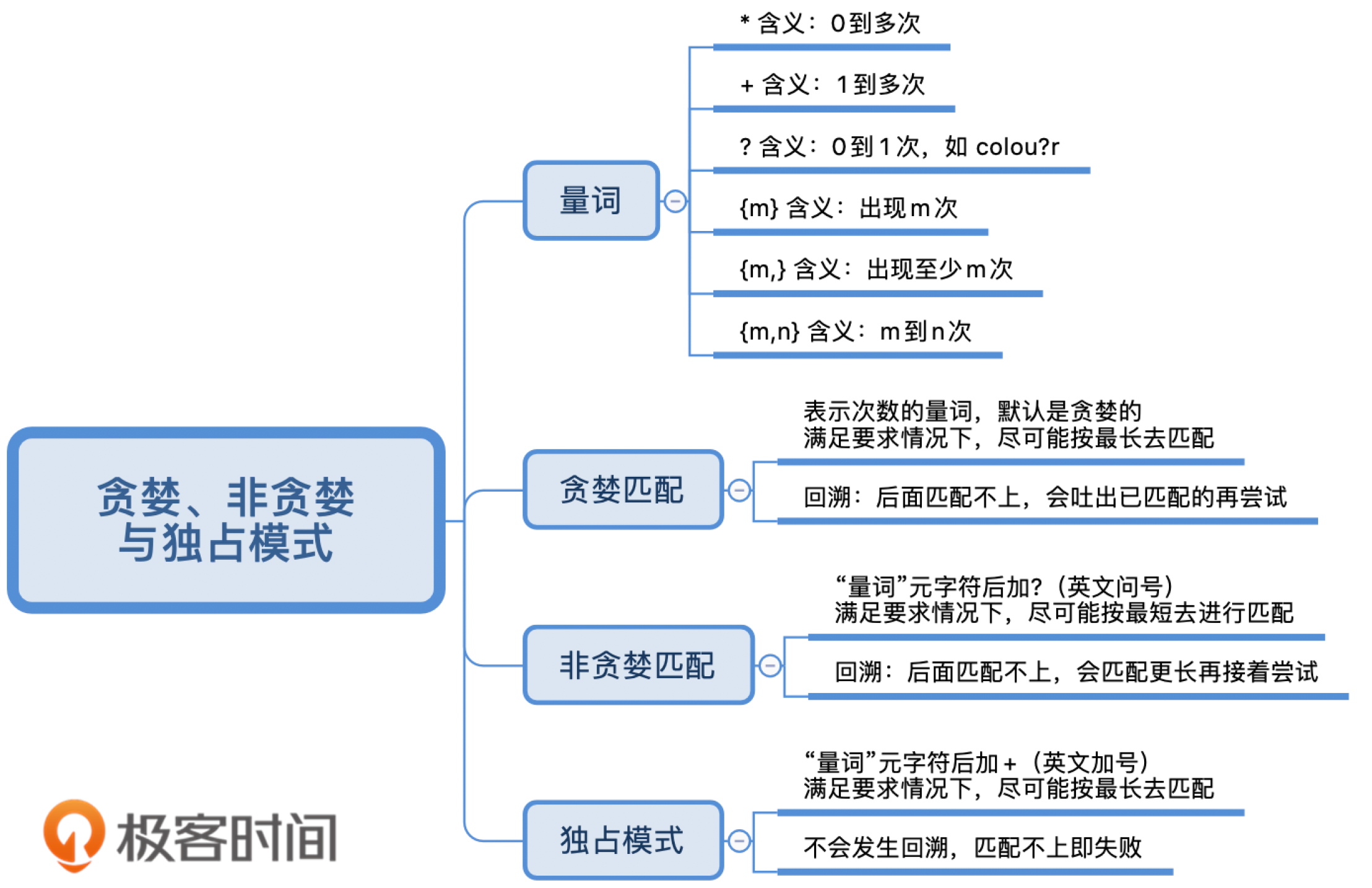
正则中的三种模式,贪婪匹配、非贪婪匹配和独占模式
贪婪模式,简单说就是尽可能进行最长匹配。非贪婪模式呢,则会尽可能进行最短匹配
贪婪匹配(Greedy)
表示次数的量词 默认是贪婪 尽可能多的匹配
非贪婪匹配(Lazy)
"数量"元字符后面加? 找出长度最小且满足要求的
独占模式(Possessive)
"数量"元字符后面加+ 尽可能长的去匹配 不会发生回溯
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+)。
总结
正则中量词默认是贪婪匹配,如果想要进行非贪婪匹配需要在量词后面加上问号。贪婪和非贪婪匹配都可能会进行回溯,独占模式也是进行贪婪匹配,但不进行回溯
03 | 分组与引用:如何用正则实现更复杂的查找和替换操作?
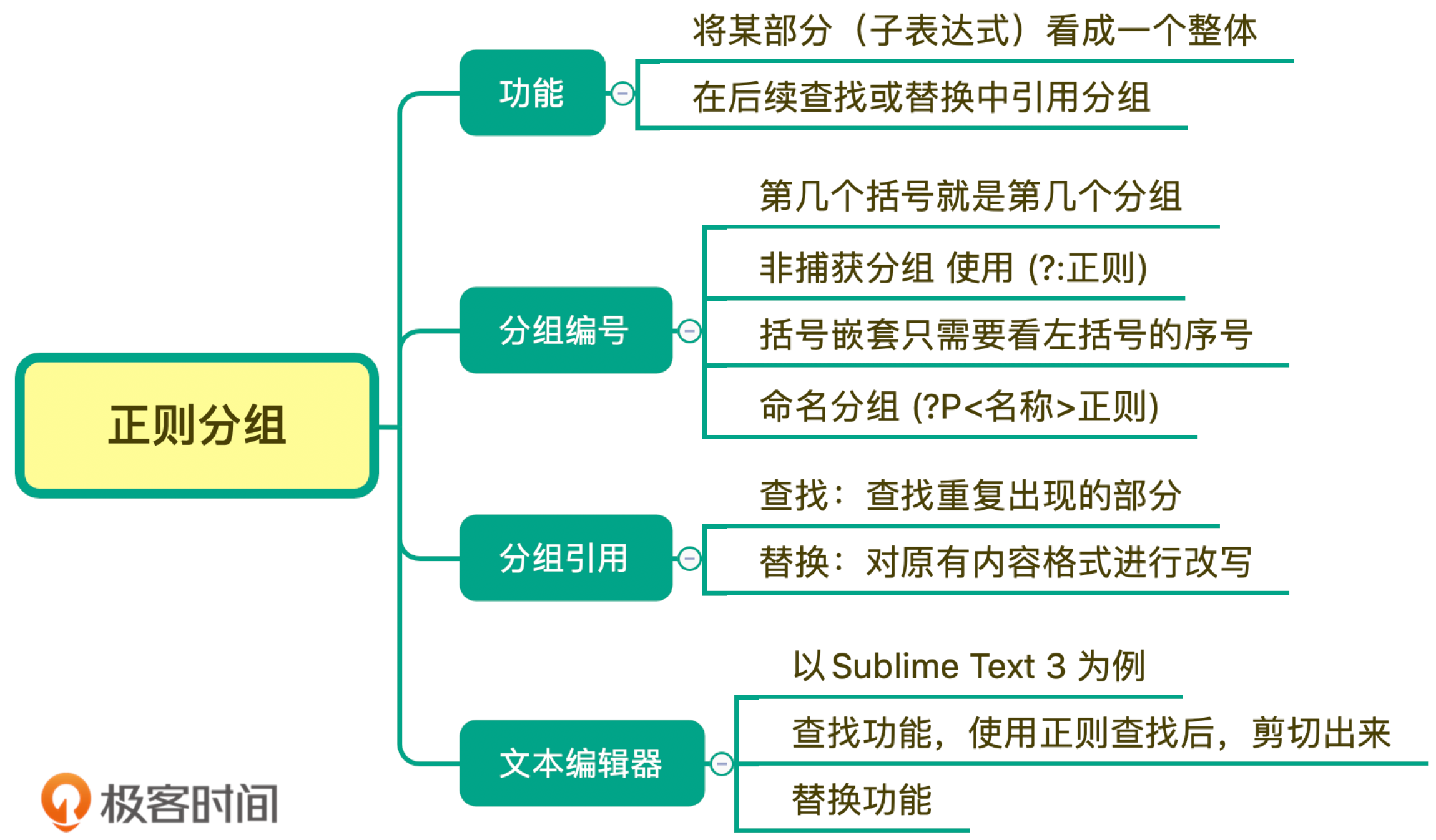
分组与编号
括号在正则中可以用于分组,被括号括起来的部分“子表达式”会被保存成一个子组
\d{15}(\d{3})?不保存子组
在括号里面的会保存成子组,但有些情况下,你可能只想用括号将某些部分看成一个整体,后续不用再用它,类似这种情况,在实际使用时,是没必要保存子组的。这时我们可以在括号里面使用 ?: 不保存子组。
\d{15}(?:\d{3})?如果正则中出现了括号,那么我们就认为,这个子表达式在后续可能会再次被引用,所以不保存子组可以提高正则的性能
括号嵌套
我们只需要数左括号(开括号)是第几个,就可以确定是第几个子组
命名分组
命名分组的格式为(?P<分组名>正则)。
分组引用
在知道了分组引用的编号 (number)后,大部分情况下,我们就可以使用 “反斜扛 + 编号”,即 \number 的方式来进行引用,而 JavaScript 中是通过$编号来引用,如$1
var re = /(\w+)\s(\w+)/;
var str = "John Smith";
var newstr = str.replace(re, "$2, $1");
console.log(newstr);
// Smith, John总结
今天我们学习到了正则中的分组和子组编号相关内容。括号可以将某部分括起来,看成一个整体,也可以保存成一个子组,在后续查找替换的时候使用。分组编号是指,在正则中第几个括号内就是第几个分组,而嵌套括号我们只要看左括号是第几个就可以了。如果不想将括号里面的内容保存成子组,可以在括号里面加上?: 来解决。
04 | 匹配模式:一次性掌握正则中常见的 4 种匹配模式
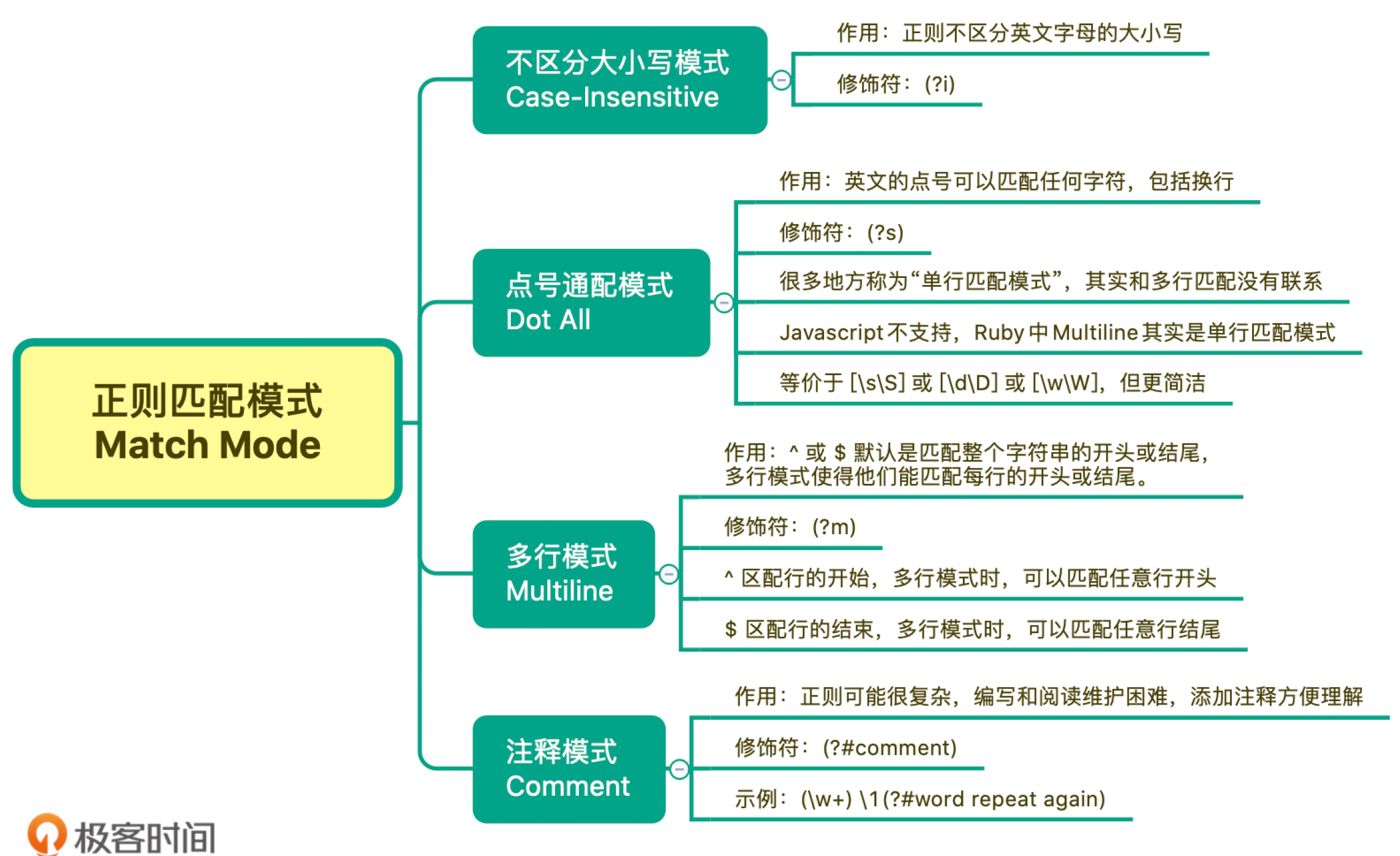
常见的匹配模式有 4 种,分别是不区分大小写模式、点号通配模式、多行模式和注释模式
不区分大小写模式(Case-Insensitive)
模式修饰符是通过 (? 模式标识) 的方式来表示的。
当我们把模式修饰符放在整个正则前面时,就表示整个正则表达式都是不区分大小写的。
(?i)cat
(?i)(cat) \1上面讲到的通过修饰符指定匹配模式的方式,在大部分编程语言中都是可以直接使用的,但在 JS 中我们需要使用 /regex/i 来指定匹配模式
到这里我简单总结一下不区分大小写模式的要点:
- 不区分大小写模式的指定方式,使用模式修饰符 (?i);
- 修饰符如果在括号内,作用范围是这个括号内的正则,而不是整个正则;
- 使用编程语言时可以使用预定义好的常量来指定匹配模式
点号通配模式(Dot All)
正则中提供了一种模式,让英文的点(.)可以匹配上包括换行的任何字符。这个模式就是点号通配模式。点号通配模式对应的修饰符是 (?s),
(?s).+ # .可以匹配换行多行匹配模式(Multiline)
^ 匹配整个字符串的开头,$ 匹配整个字符串的结尾
多行模式的作用在于,使 ^ 和 $ 能匹配上每行的开头或结尾,我们可以使用模式修饰符号(?m) 来指定这个模式。
(?m)^the|cat$注释模式(Comment)
正则中注释模式是使用(?#comment) 来表示。
(\w+)(?#word) \1(?#word repeat again)总结
正则中常见的四种匹配模式,分别是:不区分大小写、点号通配模式、多行模式和注释模式。
- 不区分大小写模式,它可以让整个正则或正则中某一部分进行不区分大小写的匹配。
- 点号通配模式也叫单行匹配,改变的是点号的匹配行为,让其可以匹配任何字符,包括换行。
- 多行匹配说的是 ^ 和 $ 的匹配行为,让其可以匹配上每行的开头或结尾。
- 注释模式则可以在正则中添加注释,让正则变得更容易阅读和维护。
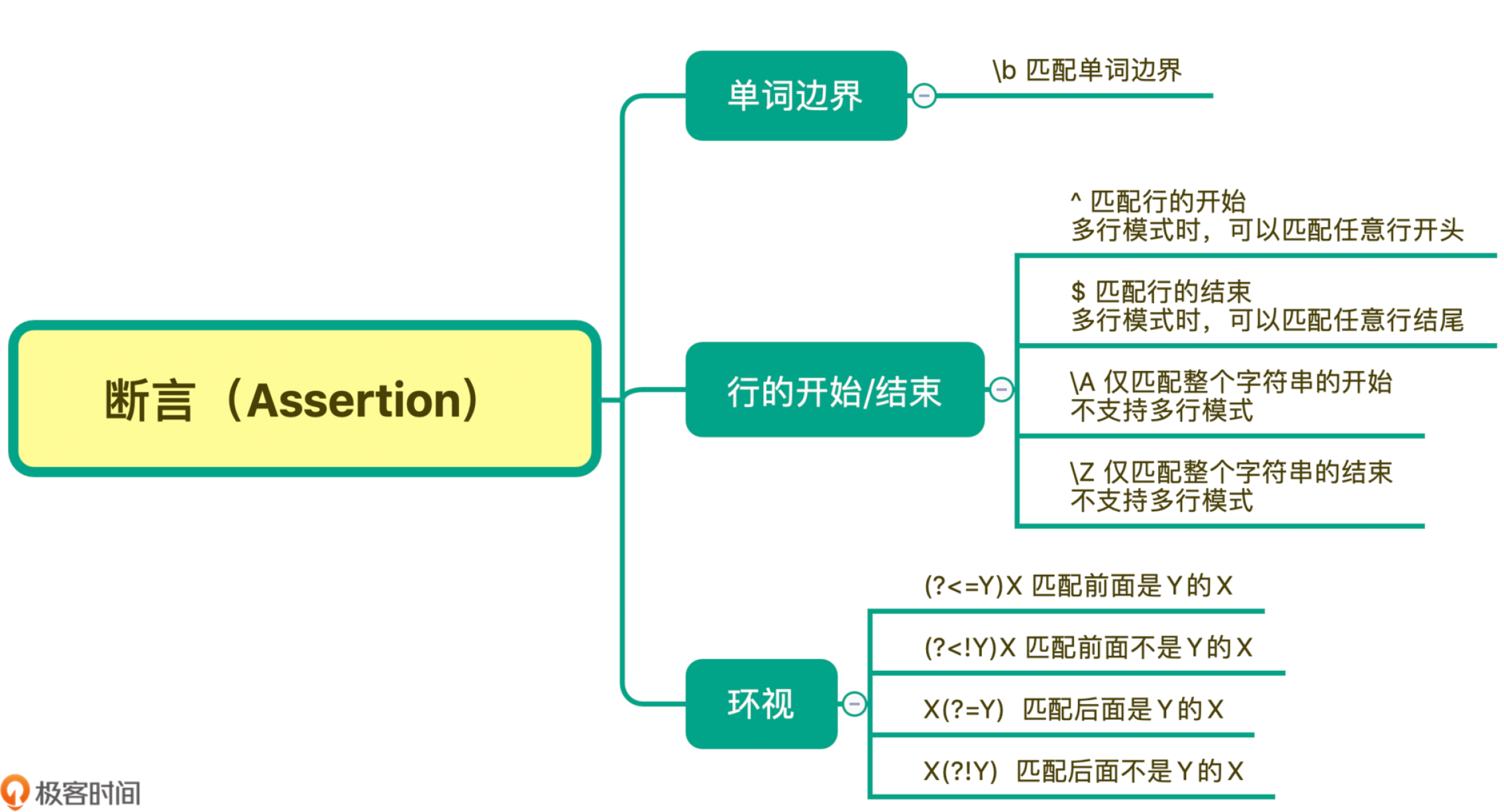
05 | 断言:如何用断言更好地实现替换重复出现的单词?
断言是指对匹配到的文本位置有要求
常见的断言有三种:单词边界、行的开始或结束以及环视
单词边界(Word Boundary)
在正则中使用\b 来表示单词的边界。
行的开始或结束
和单词的边界类似,在正则中还有文本每行的开始和结束,如果我们要求匹配的内容要出现在一行文本开头或结尾,就可以使用 ^ 和 $ 来进行位置界定
环视( Look Around)
环视就是要求匹配部分的前面或后面要满足(或不满足)某种规则,有些地方也称环视为零宽断言
| 正则 | 名称 | 含义 | 实例 |
|---|---|---|---|
| (?<=Y) | 肯定逆向环视 | 左边 Y | (?<=\d)th 左边是数字的 th,能匹配 9th |
| (?<!Y) | 否定逆向环视 | 左边不是 Y | (?<!\d)th 左边不是数字的 th,能匹配 health |
| (?=Y) | 肯定顺序环视 | 右边是 Y | six(?=\d)右边是数字的 six,能匹配 six6 |
| (?!Y) | 否定顺序环视 | 右边不是 Y | hi(?!\d)右边不是数字的 hi,能匹配 high |
左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思
总结
今天我们学习了正则中断言相关的内容,最常见的断言有三种:单词的边界、行的开始或结束、环视。
单词的边界是使用 \b 来表示,这个比较简单。而多行模式下,每一行的开始和结束是使用^ 和 $ 符号。如果想匹配整个字符串的开始或结束,可以使用 \A 和 \z,它们不受匹配模式的影响。
最后就是环视,它又分为四种情况:肯定逆向环视、否定逆向环视、肯定顺序环视、否定顺序环视。在使用的时候记住一个方法:有左尖括号代表看左边,没有尖括号是看右边,而感叹号是非的意思。
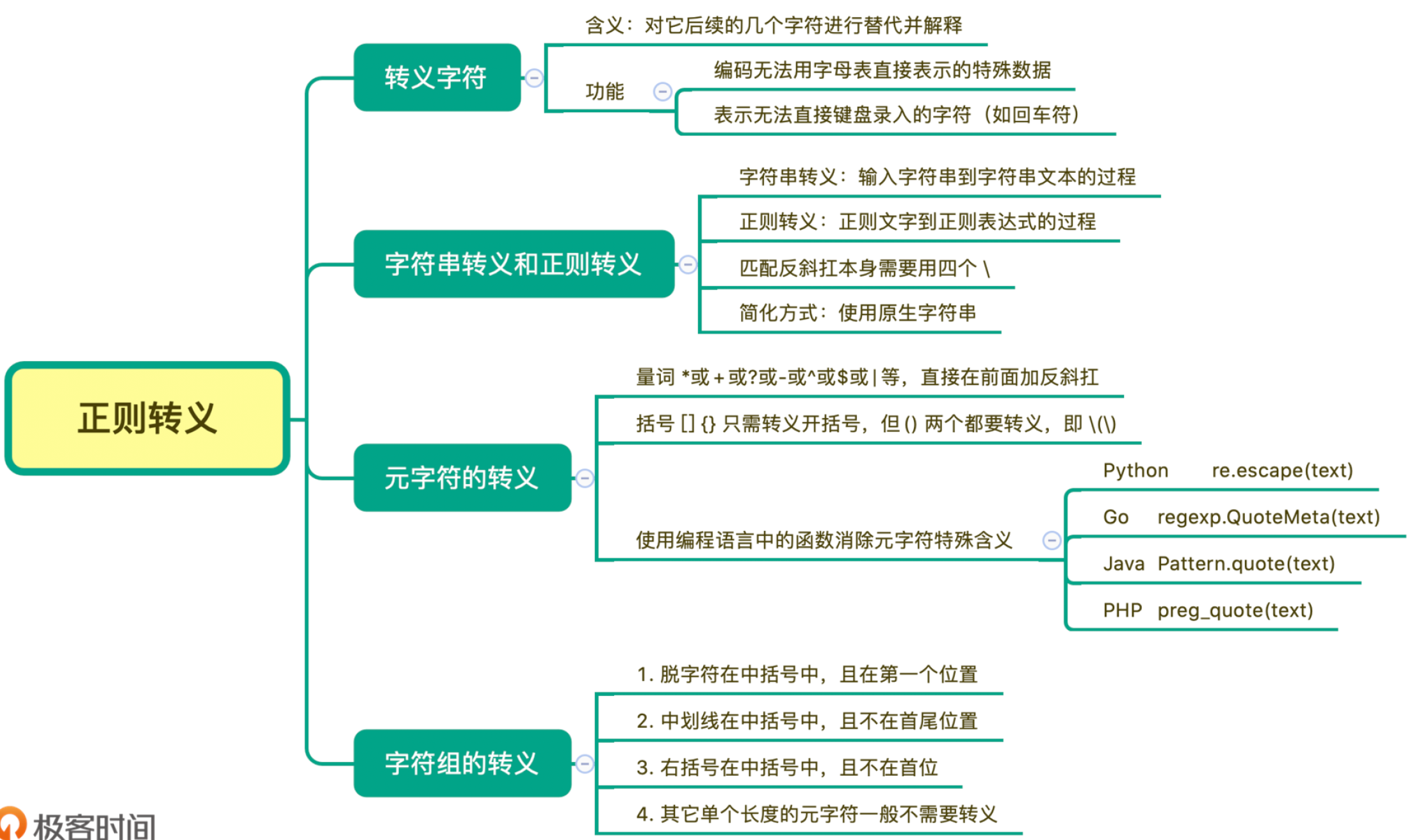
06 转义:正则中转义需要注意哪些问题?
转义序列通常有两种功能
第一种功能是编码无法用字母表直接表示的特殊数据。
第二种功能是用于表示无法直接键盘录入的字符(如回车符)。
常见的转义字符以及它们的含义
| 转义字符 | 意义 |
|---|---|
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
\\ |
反斜线 |
\' |
单引号字符 |
\" |
双引号字符 |
正则中元字符的转义
如果现在我们要查找比如星号(*)、加号(+)、问号(?)本身,而不是元字符的功能,这时候就需要对其进行转义,直接在前面加上反斜杠就可以了
字符组中需要转义的有三种情况
- ^字符在中括号中,且在第一个位置需要转义:
该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合
const str = "^ab";
const matches = str.matchAll(/[^ab]/g);
for (const match of matches) {
console.log(
`Found ${match[0]} start=${match.index} end=${
match.index + match[0].length
}.`,
);
}
// Found ^ start=0 end=1.
const res = str.matchAll(/[\^ab]/g);
for (const match of res) {
console.log(
`Found ${match[0]} start=${match.index} end=${
match.index + match[0].length
}.`,
);
}
// Found ^ start=0 end=1.
// Found a start=1 end=2.
// Found b start=2 end=3.- 中划线在中括号中,且不在首尾位置:
const str = "abc-";
// 中划线在中间,代表"范围"
const matches = str.matchAll(/[a-c]/g);
for (const match of matches) {
console.log(match[0]);
}
// a b c
const str = "abc-";
// 中划线在中间,转义后的
const matches = str.matchAll(/[a\-c]/g);
for (const match of matches) {
console.log(match[0]);
}
// a c -- 右括号在中括号中,且不在首位:
const str = "]ab";
const matches = str.matchAll(/[]ab]/g);
for (const match of matches) {
console.log(match[0]);
}
// undefined
// 转义后代表普通字符
const matches = str.matchAll(/[\]ab]/g);
for (const match of matches) {
console.log(match[0]);
}
// ] a b字符组中其它的元字符
一般来说如果我们要想将元字符(.+?() 之类)表示成它字面上本来的意思,是需要对其进行转义的,但如果它们出现在字符组中括号里,可以不转义。这种情况,一般都是单个长度的元字符,比如点号(.)、星号(*)、加号(+)、问号(?)、左右圆括号等。它们都不再具有特殊含义,而是代表字符本身。但如果在中括号中出现 \d 或 \w 等符号时,他们还是元字符本身的含义
总结
正则中转义有些情况下会比较复杂,从录入的字符串文本,到最终的正则表达式,经过了字符串转义和正则转义两个步骤。元字符的转义一般在前面加反斜杠就行,方括号和花括号的转义一般转义开括号就可以,但圆括号两个都需要转义,我们可以借助编程语言中的转义函数来实现转义。另外我们也讲了字符组中三种需要转义的情况,详细的可以参考下面的脑图
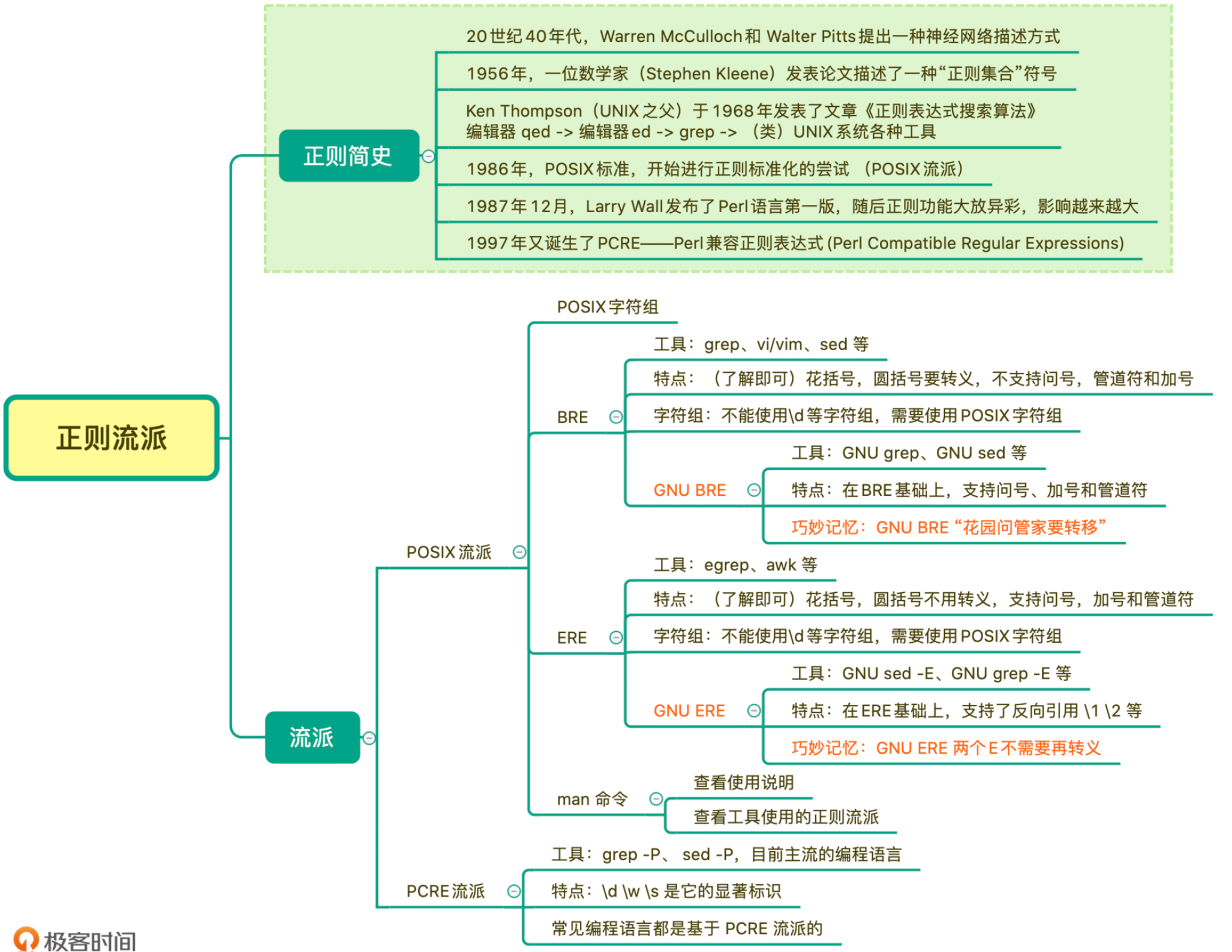
07 | 正则有哪些常见的流派及其特性?
目前正则表达式主要有两大流派(Flavor):POSIX 流派与 PCRE 流派。
POSIX 流派
POSIX 规范定义了正则表达式的两种标准:
- BRE 标准(Basic Regular Expression 基本正则表达式);
- ERE 标准(Extended Regular Expression 扩展正则表达式)。
POSIX 流派还有一个特殊的地方,就是有自己的字符组,叫 POSIX 字符组
PCRE 流派
目前大部分常用编程语言都是源于 PCRE 标准,这个流派显著特征是有\d、\w、\s 这类字符组简记方式。
在 Linux 中使用正则
在遵循 POSIX 规范的 UNIX/LINUX 系统上,按照 BRE 标准 实现的有 grep、sed 和 vi/vim 等,而按照 ERE 标准 实现的有 egrep、awk 等
总结
正则主要有两大流派,分别是 POSIX 流派和 PCRE 流派。其中 POSIX 流派有两个标准,分别是 BRE 标准和 ERE 标准,一般情况下,我们面对的都是 GNU BRE 和 GNU ERE。它们的主要区别在于,前者要转义。另外,POSIX 流派一个特点就是有自己的字符组 POSIX 字符组,这不同于常见的 \d 等字符组。PCRE 流派是如今大多数编程语言实现的流派,最大的特点就是支持\d\s\w 等,我们前面讲的内容也是基于这个流派进行的。
grep、sed、vi/vim 等属于 BRE 标准,egrep、awk 属于 ERE 标准。而 sed -P、grep -P 等属于 PCRE 流派。这些也不需要死记硬背,使用时用 man 命令看一下就好了。
如果你需要在类 Unix 平台命令等上使用正则,使用前需要搞清楚工具属于哪个标准,比如
GNU ERE 名称中有两个 E,不需要再转义。而 GNU BRE 只有一个 E,使用时“花圆问管加”时都要转义
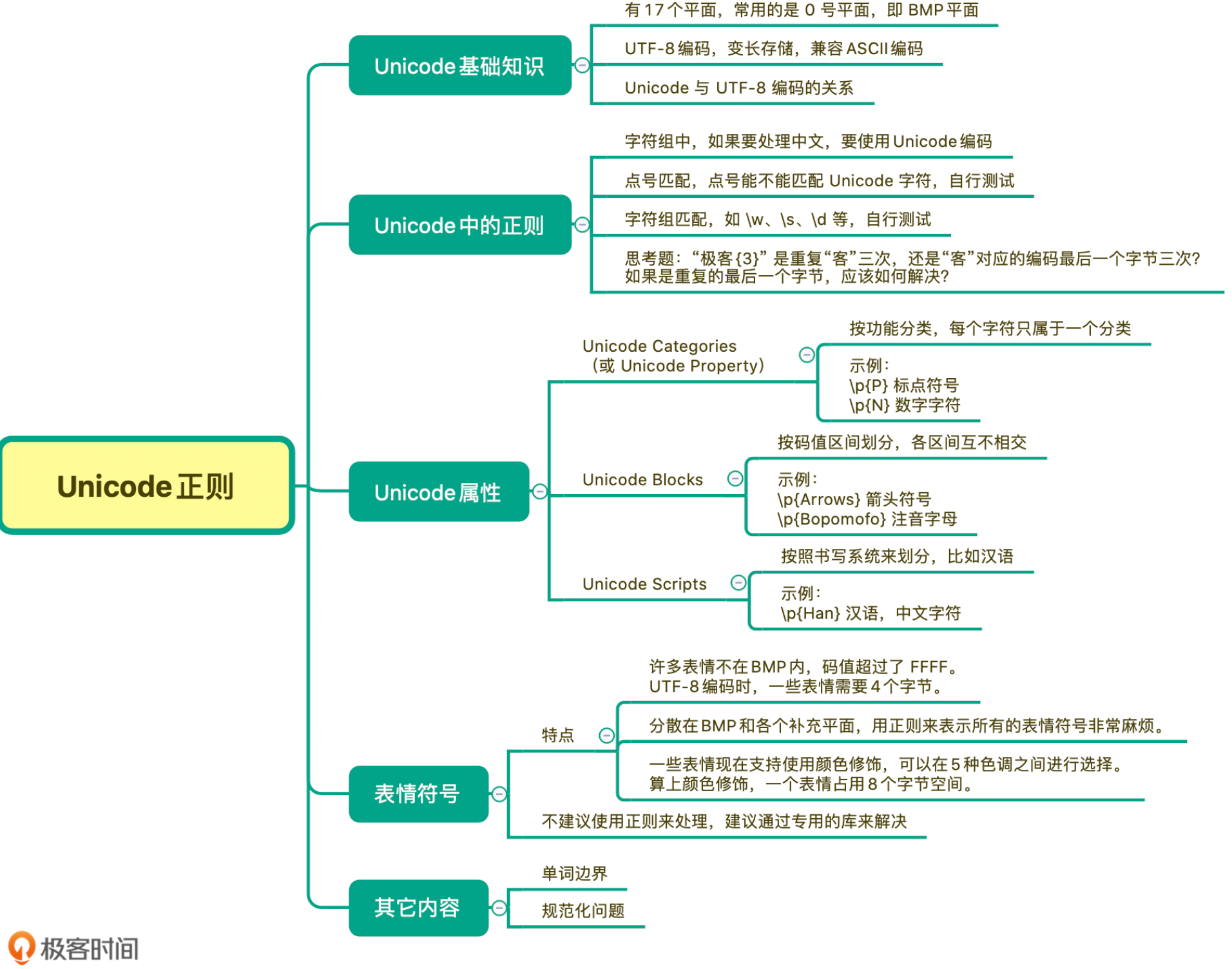
08 | 应用 1:正则如何处理 Unicode 编码的文本?
编码问题的坑
如果你在编程语言中使用正则,编码问题可能会让正则的匹配行为很奇怪。先说结论,在使用时一定尽可能地使用 Unicode 编码。
总结
10 | 应用 3:如何在语言中用正则让文本处理能力上一个台阶?
在进行文本处理时,正则解决的问题大概可以分成四类,分别是校验文本内容、提取文本内容、替换文本内容、切割文本内容
校验文本内容
// 方法1
/^\d{4}-\d{2}-\d{2}$/.test("2020-06-01"); // true
// 方法2
var regex = new RegExp(/^\d{4}-\d{2}-\d{2}$/);
regex.test("2020-01-01"); // true
// 方法3
var regex = /^\d{4}-\d{2}-\d{2}$/;
"2020-06-01".search(regex) == 0; // true提取文本内容
// 使用g模式,查找所有符合要求的内容
"2020-06 2020-07".match(/\d{4}-\d{2}/g);
// 输出:["2020-06", "2020-07"]
// 不使用g模式,找到第一个就会停下来
"2020-06 2020-07".match(/\d{4}-\d{2}/);
// 输出:["2020-06", index: 0, input: "2020-06 2020-07", groups: undefined]替换文本内容
// 使用g模式,替换所有的
"02-20-2020 05-21-2020".replace(/(\d{2})-(\d{2})-(\d{4})/g, "$3年$1月$2日");
// 输出 "2020年02月20日 2020年05月21日"
// 不使用 g 模式时,只替换一次
"02-20-2020 05-21-2020".replace(/(\d{2})-(\d{2})-(\d{4})/, "$3年$1月$2日");
// 输出 "2020年02月20日 05-21-2020"切割文本内容
"apple, pear! orange; tea".split(/\W+/);
// 输出:["apple", "pear", "orange", "tea"]
// 传入第二个参数的情况
"apple, pear! orange; tea".split(/\W+/, 1);
// 输出 ["apple"]
"apple, pear! orange; tea".split(/\W+/, 2);
// 输出 ["apple", "pear"]
"apple, pear! orange; tea".split(/\W+/, 10);
// 输出 ["apple", "pear", "orange", "tea"]11 | 如何理解正则的匹配原理以及优化原则?
有穷状态自动机
正则之所以能够处理复杂文本,就是因为采用了有穷状态自动机(finite automaton)。
那什么是有穷自动机呢?有穷状态是指一个系统具有有穷个状态,不同的状态代表不同的意义。自动机是指系统可以根据相应的条件,在不同的状态下进行转移。从一个初始状
态,根据对应的操作(比如录入的字符集)执行状态转移,最终达到终止状态(可能有一到多个终止状态)。
有穷自动机的具体实现称为正则引擎,主要有 DFA 和 NFA 两种,其中 NFA 又分为传统的 NFA 和 POSIX NFA
DFA: 确定性有穷自动机(Deterministic finite automaton)
NFA: 非确定性有穷自动机(Non-deterministic finite automaton)
DFA & NFA 工作机制
DFA 会先看文本,再看正则表达式,是以文本为主导的。
NFA 先看正则,再看文本,而且以正则为主导
一般来说,DFA 引擎会更快一些,因为整个匹配过程中,字符串只看一遍,不会发生回
溯,相同的字符不会被测试两次。也就是说 DFA 引擎执行的时间一般是线性的。
NFA 以表达式为主导,它的引擎是使用贪心匹配回溯算法实现
正则优化建议
- 测试性能的方法
- 提前编译好正则
- 尽量准确表示匹配范围
- 提取出公共部分
- 出现可能性大的放左边
- 只在必要时才使用子组
- 警惕嵌套的子组重复
- 避免不同分支重复匹配
12 | 问题集锦:详解正则常见问题及解决方案
问题处理思路
比如将问题分解成多个小问题,每个小问题见招拆招,某个位置上可能有多个字符的话,就⽤字符组。某个位置上有多个字符串的话,就⽤多选结构。出现的次数不确定的话,就⽤量词。对出现的位置有要求的话,就⽤锚点锁定位置
在正则中比较难的是某些字符不能出现,这个情况又可以进一步分为组成中不能出现,和要查找的内容前后不能出现。后一种用环视来解决就可以了,如果是要查找的内容中不能出现某些字符,这种情况比较简单,可以通过使用中括号来排除字符组,比如非元音字母可以使用 [^aeiou]来表示
常见问题及解决方案
-
匹配数字
数字的匹配比较简单,通过我们学习的字符组,量词等就可以轻松解决。
数字在正则中可以使用 \d 或 [0-9] 来表示。
如果是连续的多个数字,可以使用 \d+ 或 [0-9]+。
如果 n 位数据,可以使用 \d{n}。
如果是至少 n 位数据,可以使用 \d{n,}。
如果是 m-n 位数字,可以使用 \d{m,n}。 -
匹配正数、负数和小数
如果希望正则能匹配到比如 3,3.14,-3.3,+2.7 等数字,需要注意的是,开头的正负符号可能有,也可能没有,所以可以使用 [-+]? 来表示,小数点和后面的内容也不一定会有,所以可以使用 (?:.\d+)? 来表示,因此匹配正数、负数和小数的正则可以写成 [-+]?\d+(?:.\d+)?
非负整数,包含 0 和 正整数,可以表示成[1-9]\d*|0
非正整数,包含 0 和 负整数,可以表示成-[1-9]\d*|0 -
浮点数
其中表示正负的符号和小数点可能有,也可能没有,直接用 [-+]?\d+(?:.\d+)? 来表示。
负数浮点数表示:-\d+(?:.\d+)?
正数浮点数表示:+?(?:\d+(?:.\d+)?|.\d+) -
十六进制数
十六进制的数字除了有 0-9 之外,还会有 a-f(或 A-F) 代表 10 到 15 这 6 个数字,所以
正则可以写成 [0-9A-Fa-f]+ -
手机号码
如果只限制前 2 位,可以表示成 1[3-9]\d -
身份证号码
[1-9]\d{14}(\d\d[0-9Xx])? -
邮政编码
[1-9]\d -
中文字符
[\u4E00-\u9FFF] -
IPv4 地址
\d{1,3}(.\d{1,3}) -
日期和时间
\d{4}-(?:1[0-2]|0?[1-9])-(?:[12]\d|3[01]|0?[1-9]) -
邮箱
[a-zA-Z0-9_.±]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+
原文链接: https://jesse121.github.io/blog/articles/2021/10/27.html
版权声明: 转载请注明出处.