跳表这种数据结构对你来说,可能会比较陌生,因为一般的数据结构和算法书籍里都不怎么会讲。但是它确实是一种各方面性能都比较优秀的动态数据结构,可以支持快速地插入、删除、查找操作,写起来也不复杂,甚至可以替代红黑树(Red-black tree)。
如何理解“跳表”?
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
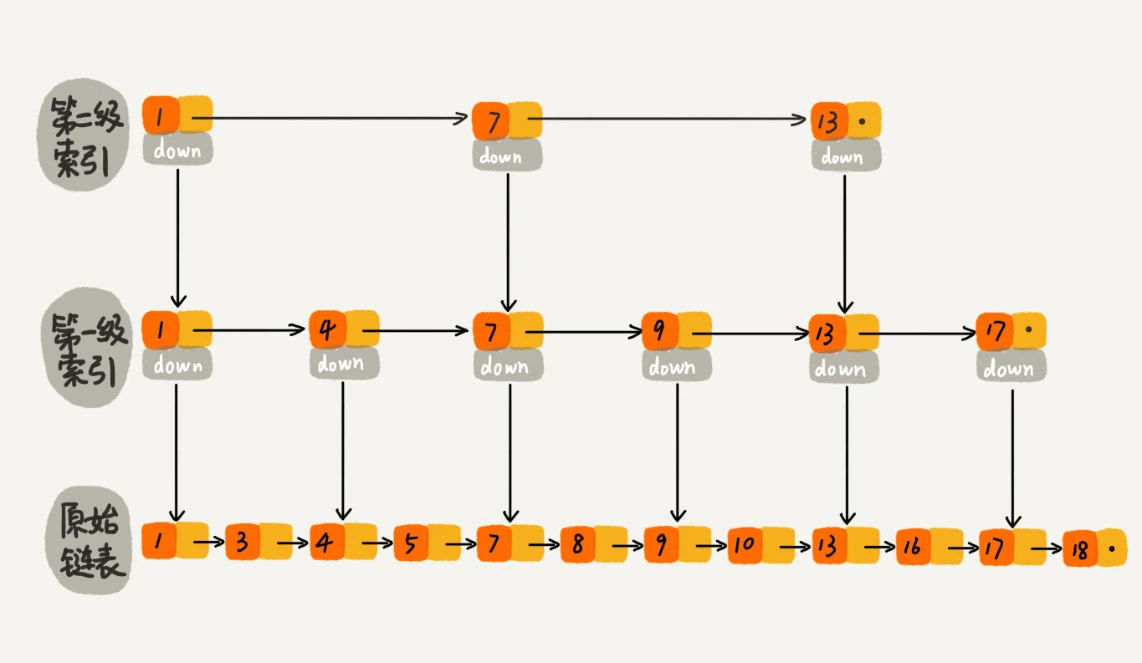
那怎么来提高查找效率呢?如果像图中那样,对链表建立一级“索引”,查找起来是不是就会更快一些呢?每两个结点提取一个结点到上一级,我们把抽出来的那一级叫做索引或索引层。加来一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。这种链表加多级索引的结构,就是跳表。
用跳表查询到底有多快?
如果链表里有 n 个结点 按照我们刚才讲的,每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k 级索引结点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点。
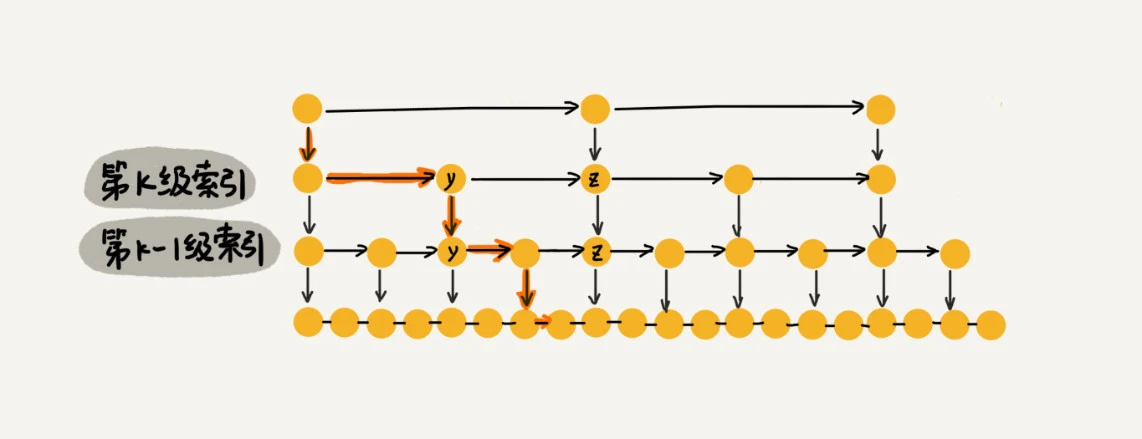
通过上面的分析,我们得到 m=3,所以在跳表中查询任意数据的时间复杂度就是 O(logn)。
跳表是不是很浪费内存?
比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。
假设原始链表大小为 n,那第一级索引大约有 n/2 个结点,第二级索引大约有 n/4 个结点,以此类推,每上升一级就减少一半,直到剩下 2 个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。

这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。
高效的动态插入和删除
跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 O(logn)。
对于纯粹的单链表,需要遍历每个结点,来找到插入的位置。但是,对于跳表来说,我们讲过查找某个结点的时间复杂度是 O(logn),所以这里查找某个数据应该插入的位置,方法也是类似的,时间复杂度也是 O(logn)。
跳表索引动态更新
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。跳表是通过随机函数来维护前面提到的“平衡性”。
跳表的 js 实现
const MAX_LEVEL = 16;
class Node {
constructor({ data = -1, maxLevel = 0, refer = new Array(MAX_LEVEL) } = {}) {
this.data = data;
this.maxLevel = maxLevel;
this.refer = refer;
}
}
class SkipList {
constructor() {
this.head = new Node();
this.levelCount = 1;
}
randomLevel() {
let level = 1;
for (let i = 1; i < MAX_LEVEL; i++) {
if (Math.random() < 0.5) {
level++;
}
}
return level;
}
insert(value) {
const level = this.randomLevel();
const newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
const update = new Array(level).fill(new Node());
let p = this.head;
for (let i = level - 1; i >= 0; i--) {
while (p.refer[i] !== undefined && p.refer[i].data < value) {
p = p.refer[i];
}
update[i] = p;
}
for (let i = 0; i < level; i++) {
newNode.refer[i] = update[i].refer[i];
update[i].refer[i] = newNode;
}
if (this.levelCount < level) {
this.levelCount = level;
}
}
find(value) {
if (!value) {
return null;
}
let p = this.head;
for (let i = this.levelCount - 1; i >= 0; i--) {
while (p.refer[i] !== undefined && p.refer[i].data < value) {
p = p.refer[i];
}
}
if (p.refer[0] !== undefined && p.refer[0].data === value) {
return p.refer[0];
}
return null;
}
remove(value) {
let _node;
let p = this.head;
const update = new Array(new Node());
for (let i = this.levelCount - 1; i >= 0; i--) {
while (p.refer[i] !== undefined && p.refer[i].data < value) {
p = p.refer[i];
}
update[i] = p;
}
if (p.refer[0] !== undefined && p.refer[0].data === value) {
_node = p.refer[0];
for (let i = 0; i <= this.levelCount - 1; i++) {
if (
update[i].refer[i] !== undefined &&
update[i].refer[i].data === value
) {
update[i].refer[i] = update[i].refer[i].refer[i];
}
}
return _node;
}
return null;
}
printAll() {
let p = this.head;
while (p.refer[0] !== undefined) {
console.log(p.refer[0].data);
p = p.refer[0];
}
}
}
test();
function test() {
let list = new SkipList();
let length = 20000;
//顺序插入
for (let i = 1; i <= 10; i++) {
list.insert(i);
}
//输出一次
list.printAll();
console.time("create length-10");
//插入剩下的
for (let i = 11; i <= length - 10; i++) {
list.insert(i);
}
console.timeEnd("create length-10");
//搜索 10次
for (let j = 0; j < 10; j++) {
let key = Math.floor(Math.random() * length + 1);
console.log(key, list.find(key));
}
//搜索不存在的值
console.log("null:", list.find(length + 1));
//搜索5000次统计时间
console.time("search 5000");
for (let j = 0; j < 5000; j++) {
let key = Math.floor(Math.random() * length + 1);
}
console.timeEnd("search 5000");
}内容小结
跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。跳表是一种动态数据结构,支持快速地插入、删除、查找操作,时间复杂度都是 O(logn)。跳表的空间复杂度是 O(n)。
原文链接: https://jesse121.github.io/blog/articles/2021/03/09.html
版权声明: 转载请注明出处.